Orange 3 is impressive
AI Machine LearningI’ve been keeping a lazy eye on Orange over the years and it’s (fairly) recent update has made it quite an impressive contender in the Data Science visual platform space. While it’s not RapidMiner, it does have a lot of great things going for it. First, it’s entire core was rewritten to tightly integrate with Scikit-Learn and Python. It has a decent time series ‘add-on’ which comes stock with ARIMA. It has a really good Text Processing ‘add-on’ that gives the user more finer control that RapidMiner’s and it has a great GEO Map natively.
Sure, there is no production server or native Hadoop connectivity but all that can be solved by easily creating a new Widget using Python and calling some Orange classes and exporting Pickle files.
Testing out Orange3
I took a few minutes yesterday and this morning to build a simple Twitter Text Processing flow. Just like RapidMiner you have to connect ‘Widgets’ together. Each Widget does a specific task. In the process below I connect to Twitter, do a search for ‘RapidMiner’ and extract the corpus. I use the NLTK package to do my stopword filtering convert the text via TF-IDF. Whenever you connect to a widget, the process executes that widget, so you don’t have hit ‘play’ all the time.
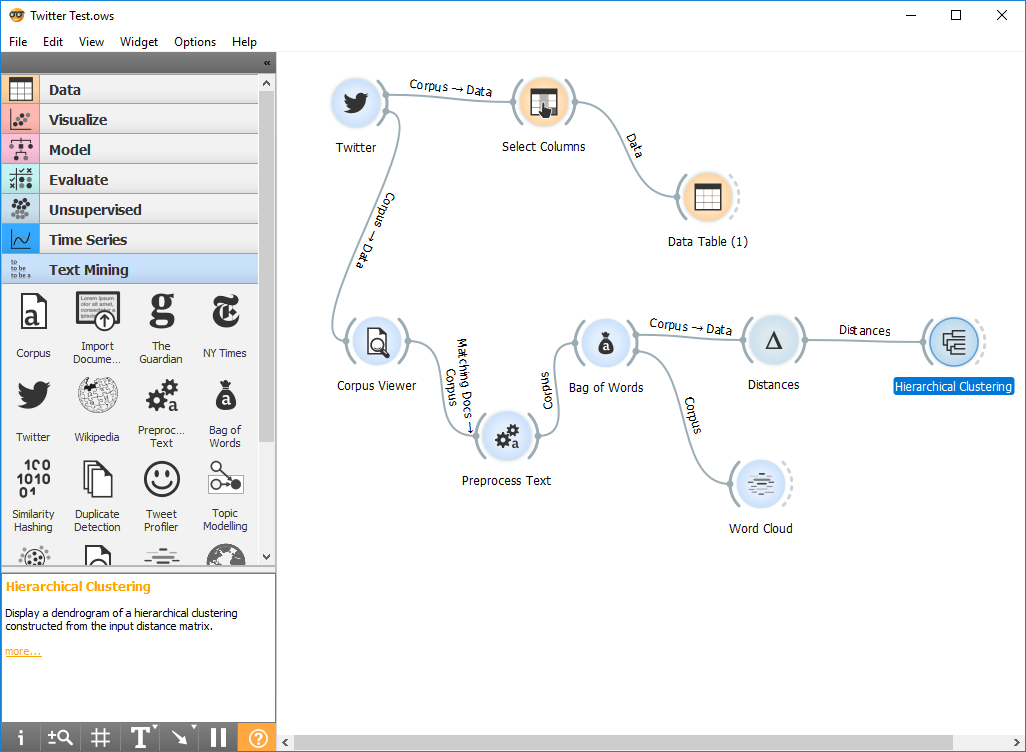
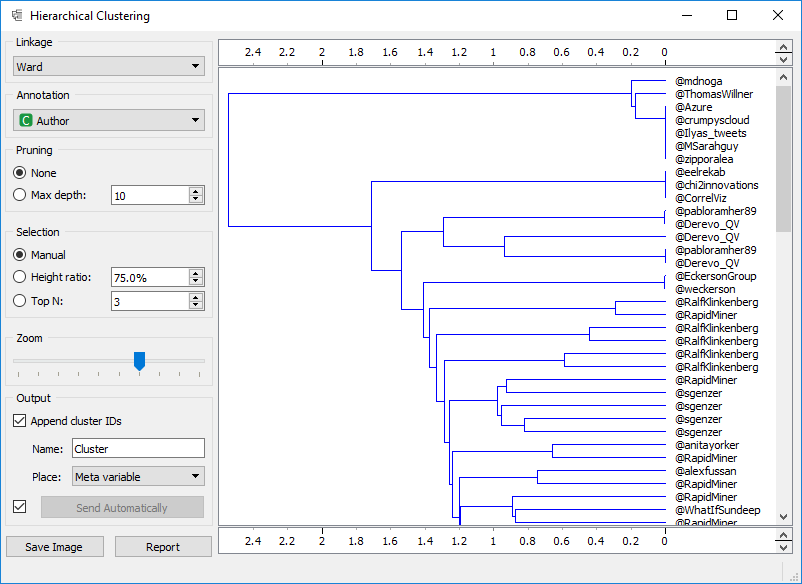
From there I do two more things, I create a word cloud and run hierarchal clustering on it.

There is a pretty rich ETL set of Widgets too and if you don’t find what you need, you can just use the Python Script widget to write your own code.
Some of the negatives I’ve encountered is that it crashes when I try to install too many ‘add-ons’ and it doesn’t feel stable enough on a Windows machine but overall, it’s quite impressive. I’m going to continue to tinker around with this software and write about it.
Update
I’m revisiting this little platform over the next few months to check it out in depth. From the surface it looks to have a low entry barrier to using AI in a visual manner. You can use it for exploration and analysis but it has no productionalization captabilities. Right now it looks like just a research tool, and that’s OK. Not ever project has to become a VC backed startup!