Lead Scoring with H2O and Streamlit
Tutorials Python Streamlit H2O.ai UIStreamlit has to be one of my favorite new libraries out there and I experiment with it when I have time. For fun I wanted to see how easy it would be to build a simple UI with Streamlit and wrap H2O-3’s AutoML into it, to build your own AutoML tool. In about 100 lines of code I was able to make a simple website that lets users upload a training data set and a scoring data set.
It runs H2O-3 AutoML for a binary type of problem and then gives you the predicted results. It’s a simple POC (Proof of Concept) but it was fun nonetheless because Streamlit is so lightweight to use.
First initialize the required Python libraries.
This is pretty straight forward, you’ll need Streamlit, Pandas, H2O, and time.
import streamlit as st
#import numpy as np
import pandas as pd
import time
import h2o
from h2o.automl import H2OAutoML
Set some environmental variables
I decided to keep this code focused on binary class problems, but with H2O-3’s AutoML you can extend it to regression type problems too. That would be for another tutorial.
All I did was set the seed number, put the max folds for Cross Validation, the early stopping metric, and the maximum models to train. If you’ve ever used AutoML from H2O, it’s really nice and powerful.
#Set some variables here (use this area to set up parameters for AutoML and datasets)
seed = 1234
nfolds = 5
stopping_metric = 'AUC'
max_models = 10
Uploading a Training and Scoring Dataset
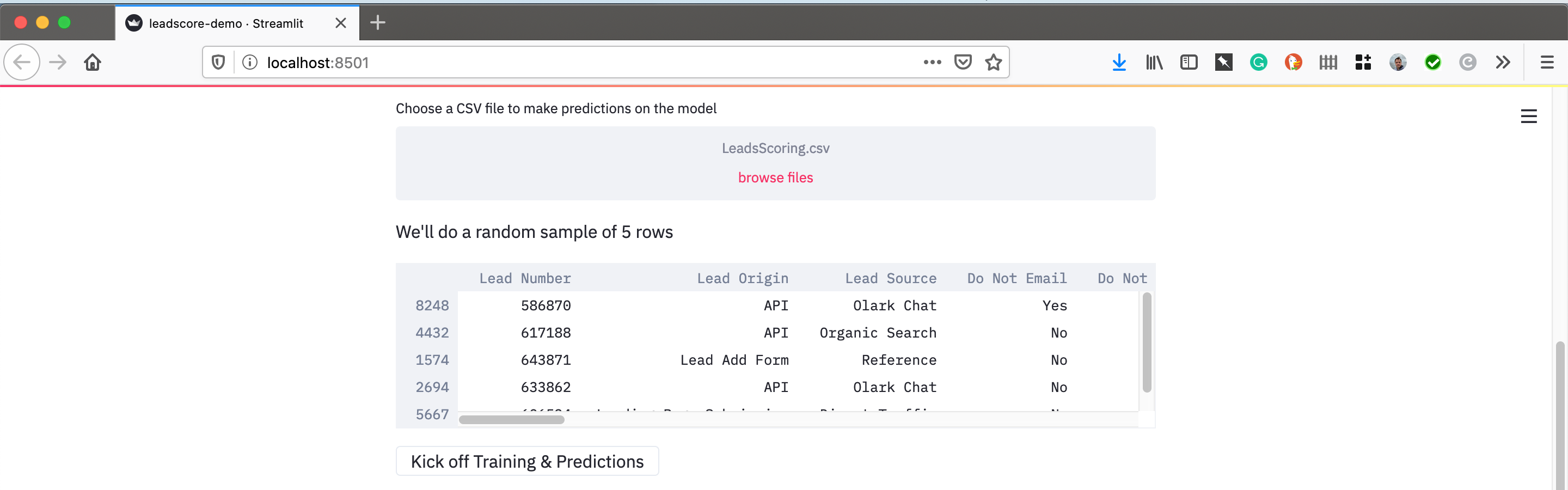
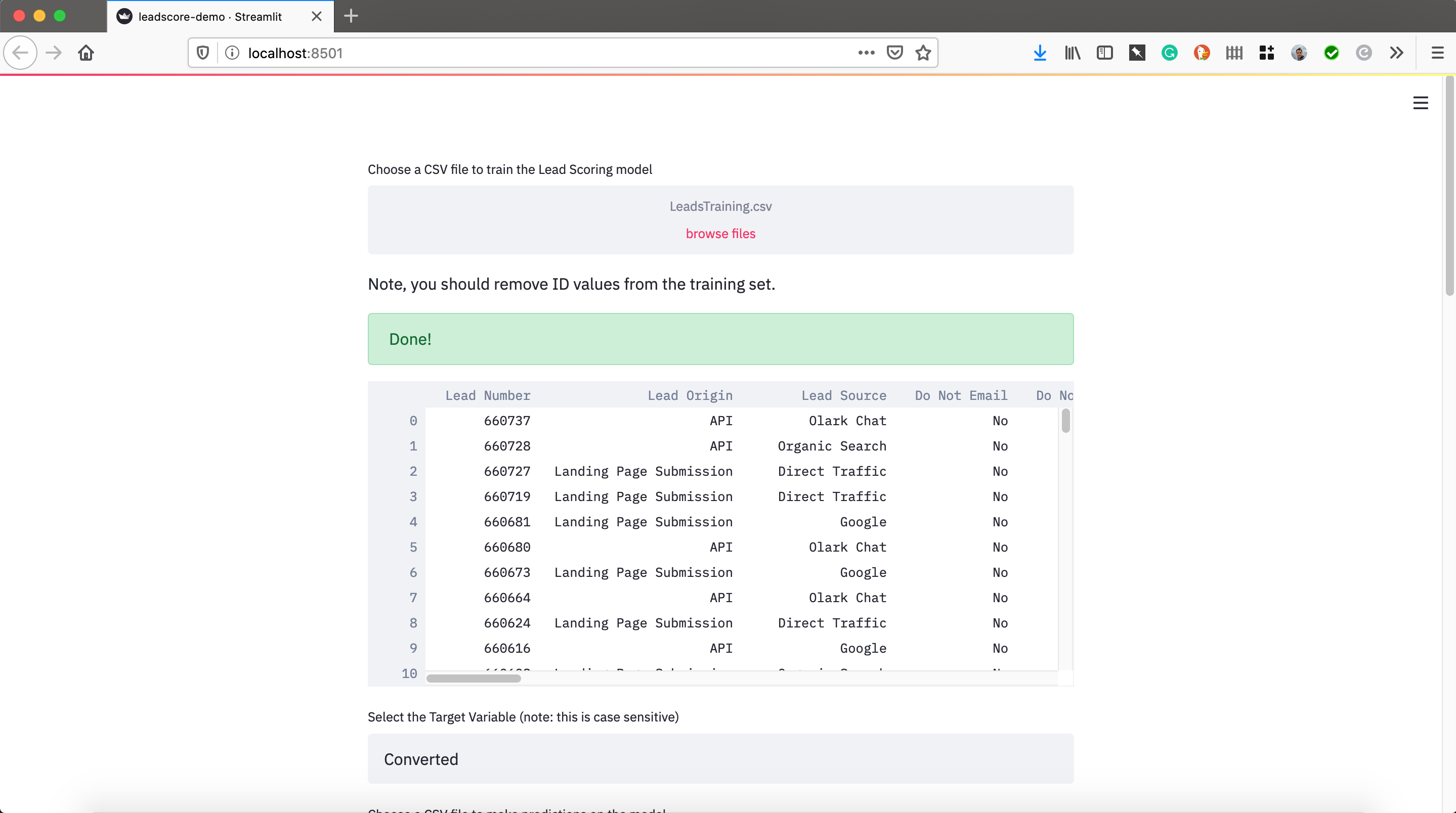
Here I just read through the Streamlit documentation to figure out how to do this. I loaded up two datasets, one for training and one for scoring. I assigned them to pandas dataframes to manipulated them and then sent them an H2O dataframe for modeling and predicting. Note, I added a random sample of the scoring data to make this go faster, you may comment that out if you like.
ploaded_file = st.file_uploader("Choose a CSV file to train the Lead Scoring model", type="csv")
st.write('Note, you should remove ID values from the training set.')
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
with st.spinner('Wait for it...'):
time.sleep(5)
st.success('Done!')
st.write(data)
target = st.text_input('Select the Target Variable (note: this is case sensitive)', 'Converted')
#ID = st.text_input('Select the ID column (note: this is case sensitive)', 'ID')
uploaded_file = st.file_uploader("Choose a CSV file to make predictions on the model", type="csv")
if uploaded_file is not None:
load = pd.read_csv(uploaded_file)
predict = load.sample(5)
st.write("We'll do a random sample of 5 rows", predict)
Kick of Training and Scoring
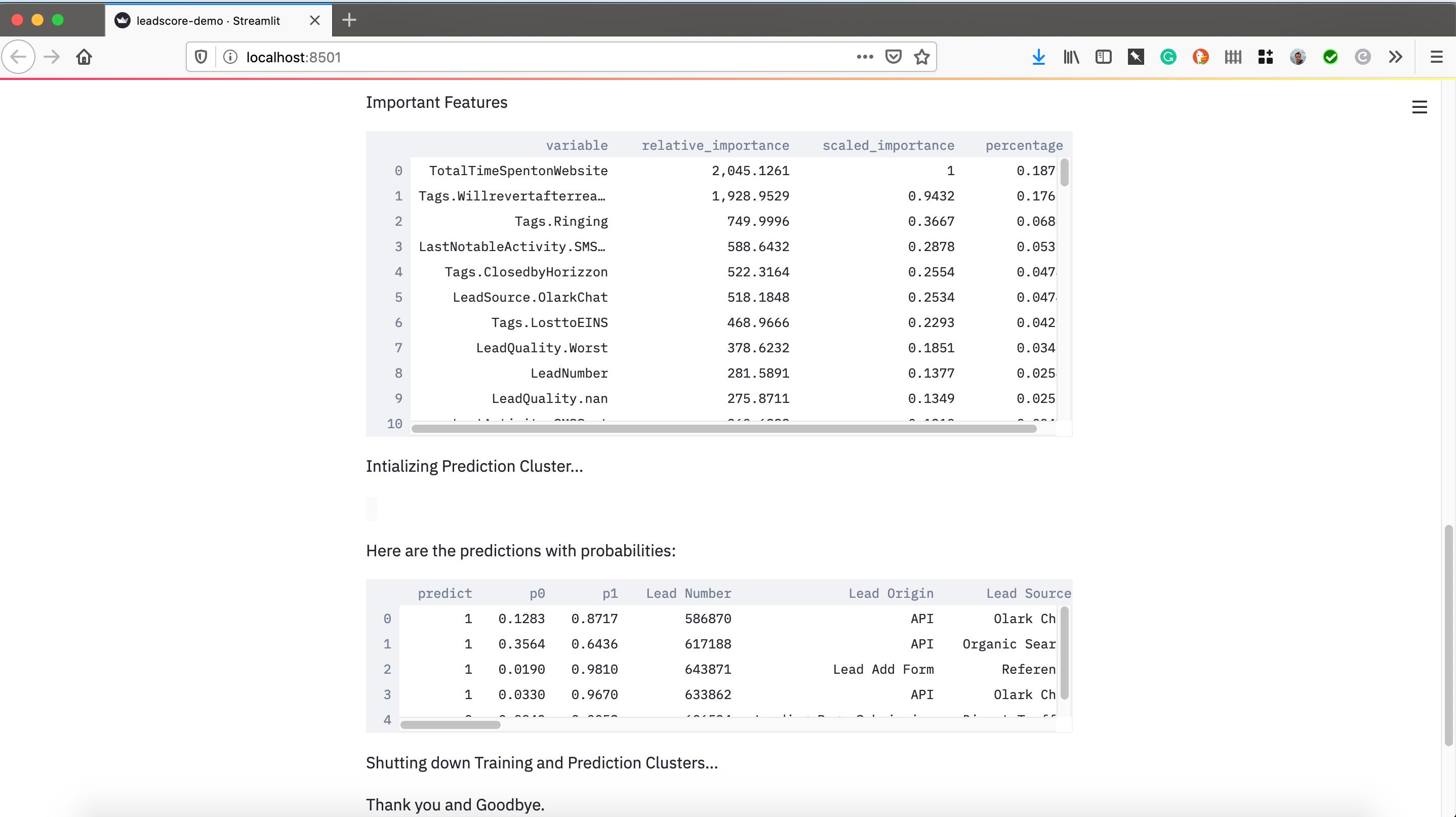
Now comes the fun part, the training and scoring. Streamlit let’s you add buttons and all kinds of standard web things to interact with your application. I just made a ‘Kick Off Training and Scoring’ button that launched the H2O cluster. It loaded in the pandas dataframe, built 10 models in AutoML, and grabbed the best model based on AUC. After that I grabbed the 2nd best model for variable importance.
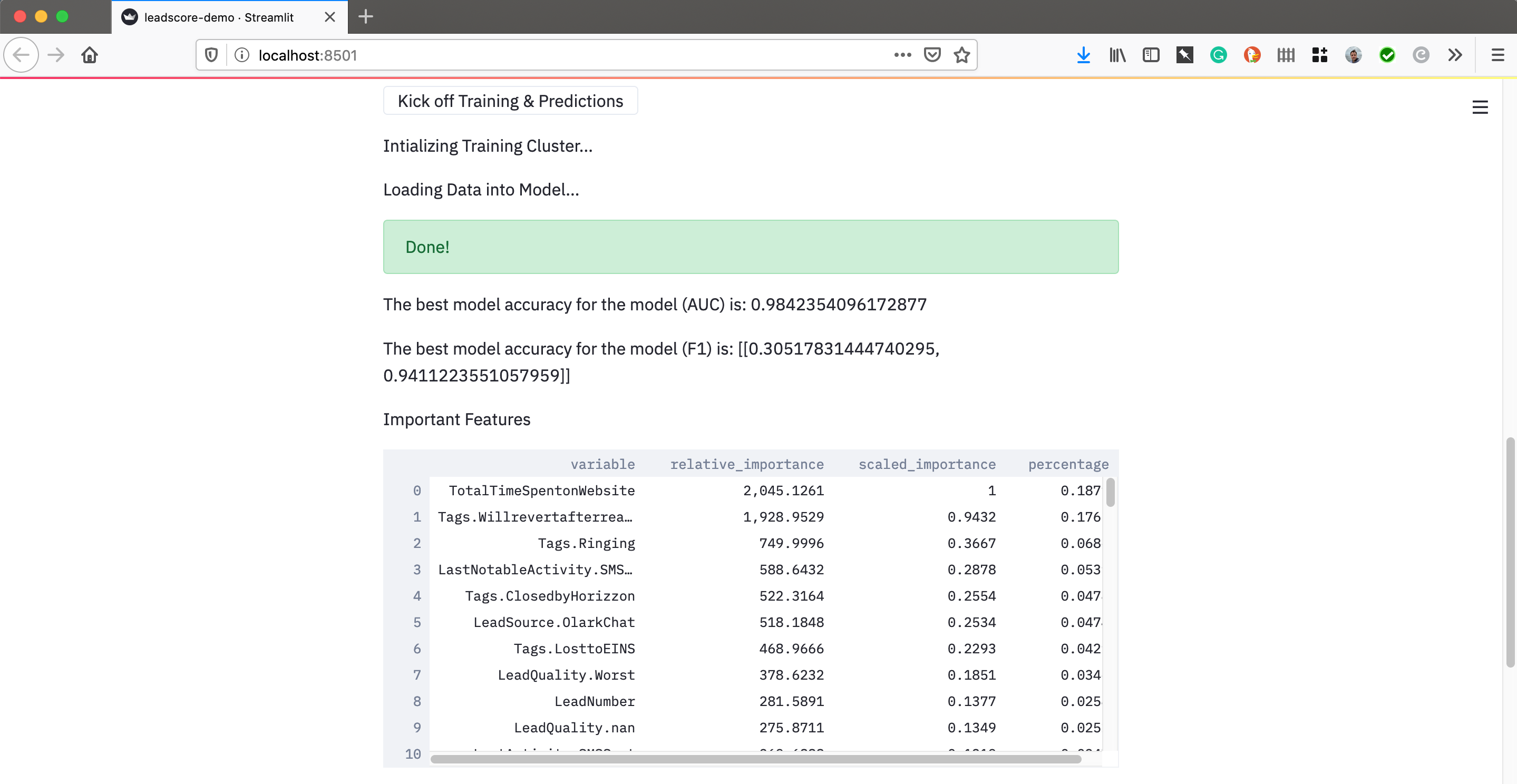
Why did I do that? There appears to be an issue with feature importance when using the top stacked ensemble model, so for this POC we just grabbed the 2nd best and lived with it.
It grabs the 2nd best model and the scores on it, displaying the results.
if st.button('Kick off Training & Predictions'):
st.write('Intializing Training Cluster...')
#Initialize H2O cluster
h2o.init()
st.write('Loading Data into Model...')
train = h2o.H2OFrame(data)
train,test= train.split_frame(ratios=[.7])
# Identify predictors and response
x = train.columns
y = target
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
# Run AutoML for 20 base models (limited to 1 hour max runtime by default)
with st.spinner('Wait for it...'):
aml = H2OAutoML(max_models=max_models, seed=seed, nfolds=nfolds, stopping_metric=stopping_metric, exclude_algos = ["StackedEnsemble", "DeepLearning", "DRF"])
aml.train(x=x, y=y, training_frame=train)
time.sleep(5)
st.success('Done!')
# View the AutoML Leaderboard
lb = aml.leaderboard
#lb.head(rows=lb.nrows)
# Get Leader Accuracy
perf_leader = aml.leader.model_performance(test).auc()
st.write("The best model accuracy for the model (AUC) is:", str(perf_leader))
perf_f1 = aml.leader.model_performance(test).F1()
st.write("The best model accuracy for the model (F1) is:", str(perf_f1))
m = h2o.get_model(lb[2,"model_id"])
FI = m.varimp(use_pandas=True)
st.write("Important Features", FI)
# Get predictions
preds = aml.predict(test)
print(preds)
predict_frame = h2o.H2OFrame(predict)
preds = aml.predict(predict_frame)
st.write('Intializing Prediction Cluster...')
st.write(preds)
tmp = preds.as_data_frame()
tmp2 = predict_frame.as_data_frame()
out = pd.merge(tmp, tmp2, left_index=True, right_index=True)
st.write('Here are the predictions with probabilities:', out)
st.write('Shutting down Training and Prediction Clusters...')
h2o.cluster().shutdown()
st.write("Thank you and Goodbye.")
else:
pass
Complete Python Code
Below is the complete code.
import streamlit as st
import numpy as np
import pandas as pd
import time
import h2o
from h2o.automl import H2OAutoML
#Set some variables here (use this area to set up parameters for AutoML and datasets)
seed = 1234
nfolds = 5
stopping_metric = 'AUC'
max_models = 10
uploaded_file = st.file_uploader("Choose a CSV file to train the Lead Scoring model", type="csv")
st.write('Note, you should remove ID values from the training set.')
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
with st.spinner('Wait for it...'):
time.sleep(5)
st.success('Done!')
st.write(data)
target = st.text_input('Select the Target Variable (note: this is case sensitive)', 'Converted')
#ID = st.text_input('Select the ID column (note: this is case sensitive)', 'ID')
uploaded_file = st.file_uploader("Choose a CSV file to make predictions on the model", type="csv")
if uploaded_file is not None:
load = pd.read_csv(uploaded_file)
predict = load.sample(5)
st.write("We'll do a random sample of 5 rows", predict)
if st.button('Kick off Training & Predictions'):
st.write('Intializing Training Cluster...')
#Initialize H2O cluster
h2o.init()
st.write('Loading Data into Model...')
train = h2o.H2OFrame(data)
train,test= train.split_frame(ratios=[.7])
# Identify predictors and response
x = train.columns
y = target
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
# Run AutoML for 20 base models (limited to 1 hour max runtime by default)
with st.spinner('Wait for it...'):
aml = H2OAutoML(max_models=max_models, seed=seed, nfolds=nfolds, stopping_metric=stopping_metric, exclude_algos = ["StackedEnsemble", "DeepLearning", "DRF"])
aml.train(x=x, y=y, training_frame=train)
time.sleep(5)
st.success('Done!')
# View the AutoML Leaderboard
lb = aml.leaderboard
#lb.head(rows=lb.nrows)
# Get Leader Accuracy
perf_leader = aml.leader.model_performance(test).auc()
st.write("The best model accuracy for the model (AUC) is:", str(perf_leader))
perf_f1 = aml.leader.model_performance(test).F1()
st.write("The best model accuracy for the model (F1) is:", str(perf_f1))
m = h2o.get_model(lb[2,"model_id"])
FI = m.varimp(use_pandas=True)
st.write("Important Features", FI)
# Get predictions
preds = aml.predict(test)
print(preds)
predict_frame = h2o.H2OFrame(predict)
preds = aml.predict(predict_frame)
st.write('Intializing Prediction Cluster...')
st.write(preds)
tmp = preds.as_data_frame()
tmp2 = predict_frame.as_data_frame()
out = pd.merge(tmp, tmp2, left_index=True, right_index=True)
st.write('Here are the predictions with probabilities:', out)
st.write('Shutting down Training and Prediction Clusters...')
h2o.cluster().shutdown()
st.write("Thank you and Goodbye.")
else:
pass
End Notes
I really simplified this and even if you got an AUC of 0.99 I would be very suspect. The dataset I experimented with was a lead scoring data set from Kaggle that had 2 leaking features and I dropped some columns because they were causing the AutoML to crash, so there’s a lot of stuff that I would need to build in the code for error checking. On top of all this, I didn’t do ANY feature engineering whatsoever so this model could use work. Plus, I should’ve added some Matplotlib or Plotly visualizations.
Still, this was a fun exercise indeed.