Isolation Forests in H2O.ai
h2oai AI Machine LearningA new feature has been added to H2O-3 open source, isolation forests. I’ve always been a fan of understanding outliers and love using One Class SVM’s as a method, but the isolation forests appear to be better in finding outliers, in most cases.
From the H2O.ai blog:
There are multiple approaches to an unsupervised anomaly detection problem that try to exploit the differences between the properties of common and unique observations. The idea behind the Isolation Forest is as follows.
- We start by building multiple decision trees such that the trees isolate the observations in their leaves. Ideally, each leaf of the tree isolates exactly one observation from your data set. The trees are being split randomly. We assume that if one observation is similar to others in our data set, it will take more random splits to perfectly isolate this observation, as opposed to isolating an outlier.
- For an outlier that has some feature values significantly different from the other observations, randomly finding the split isolating it should not be too hard. As we build multiple isolation trees, hence the isolation forest, for each observation we can calculate the average number of splits across all the trees that isolate the observation. The average number of splits is then used as a score, where the less splits the observation needs, the more likely it is to be anomalous.
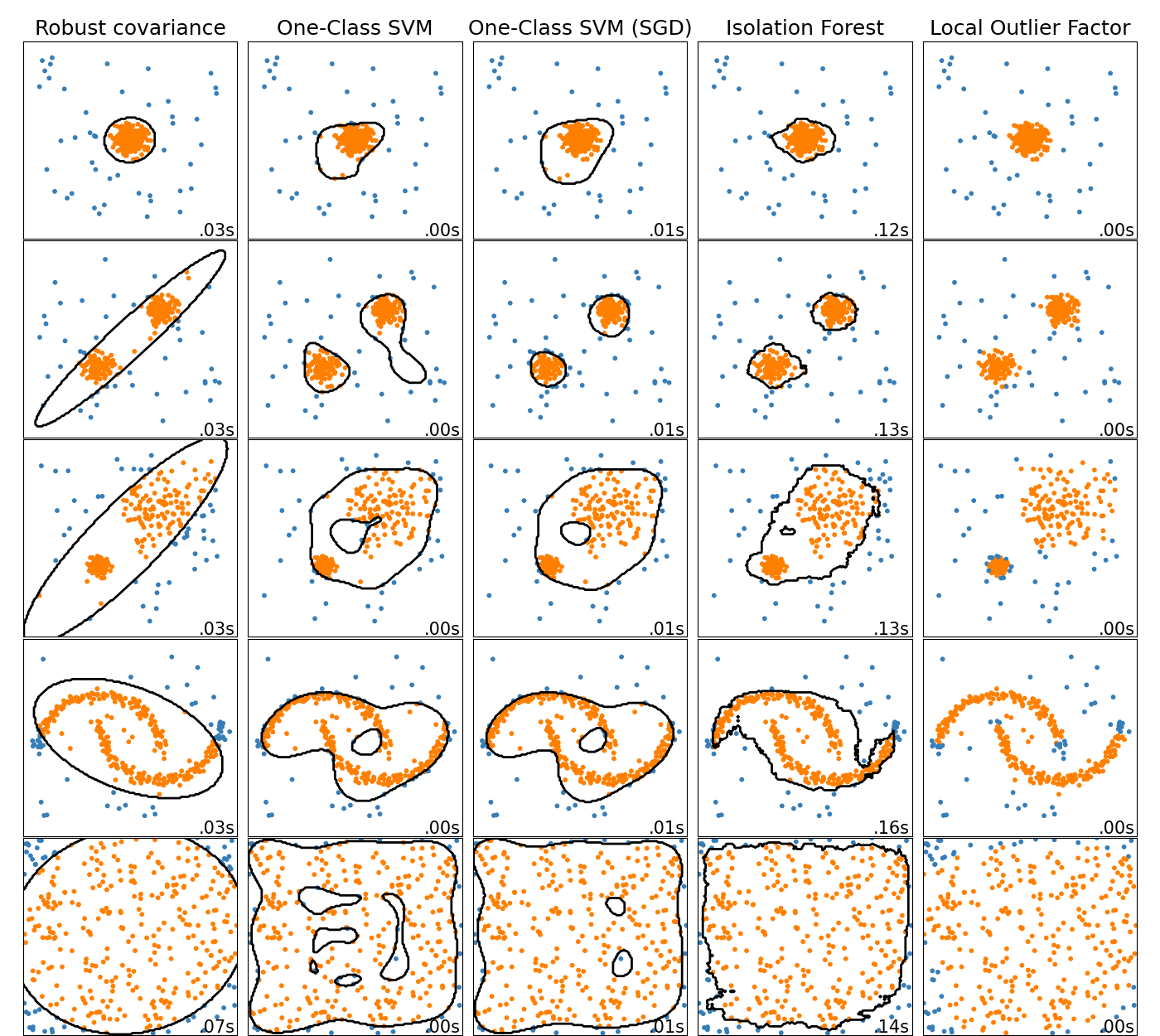
While there’s other methods of outlier detection like LOF (local outlier factor), it appears that Isolation Forests tend to be better than One Class SVM’s in finding outliers.
See this handy image from Scikit-Learn site:
Interesting indeed. I plan on using this new feature on some work I’m doing for customers.